
- 분류 전체보기 (42)

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- kt에이블스쿨7기
- KT AIVLE School
- Kafka
- kt aivleschool 8기
- 미니프로젝트
- 관세용어
- springboot
- kt 에이블스쿨 7기
- AI트랙
- kt aivleschool 7기
- KT에이블스쿨
- 데이터분석
- 기자단
- 마이크로서비스
- aice associate
- ktaivleschool
- 7일 전사
- kt aivle school 7기
- 에이블스쿨 7기
- 데이터
- 에이블스쿨 모집
- 에이블 기자단
- kt에이블스쿨 8기
- ktaivleschool7기
- MSA
- KT 에이블스쿨
- msaez
- 후기
- kt 에이블스쿨 8기
- kt에이블스쿨8기
Archives
- Today
- Total
Hseong
[KT AIVLE SCHOOL 7기] - 데이터 시각화(Matplotlib,Seaborn) 본문
728x90
반응형

데이터 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import koreanize_matplotlib
import warnings
warnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format='retina'- 먼저 matplotlib 사용을 위해 import 해주고 앞서 pandas as pd 처럼 as plt로 줄여서 쓰기로 정의한다.
# 데이터 읽어오기
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/stock.csv'
stock = pd.read_csv(path)
# 전처리
stock = stock.loc[stock['Date'].between('2022-12-01', '2022-12-31')]
stock.reset_index(drop=True, inplace=True)
stock.insert(1, 'Day', stock['Date'].str.split('-').str[2])
stock.drop('Date', axis=1, inplace=True)
# 확인
stock.head()- 그 후에 path를 통해 데이터를 받아오고, pd.read_csv 함수를 이용하여 데이터 프레임 형태로 저장한다.
- 시각화를 위해서는 전처리가 필요한데, loc 구문을 통해 'Date' 라는 열을 기준으로 between 사이에 있는 날짜들의 데이터만 전체 가져온다.
- reset_index를 통해서 기존 인덱스의 번호가 변경된 후에 다시 재정의 되어야 해서 drop=true,inplace=true 구문을 통해서 재정의 한다.
- 그 후에 drop 구문을 이용하여 axis=1 열을 뜻하므로 'Date'라는 열을 없애버린다.
- inplace = True 는 DataFrame에서 바로 수정이 이루어지도록 한다는 뜻이다. 즉, 새로운 DataFrame을 반환하지 않고 stock DataFrame 자체가 수정된다.
Matplotlib
plt.plot(stock['Close'])
plt.show()- 기본적으로 plot() 안에 데이터를 넣게되면 y 축의 값으로 들어가고, 자동으로 index 이름이 x축이 되어서 그래프가 그려진다.
- 그리고 x,y축 값을 직접 지정하여 그래프를 그릴 수도 있다. 순서는 plot(x축 데이터,y축 데이터) 순으로 넣어주면 된다!
plt.plot(stock['Day'], stock['Close'])
plt.show()
plt.plot(stock['Day'], stock['Close'])
plt.title('Stock Closing Price', size=15, pad=10)
plt.xlabel('Day')
plt.ylabel('Price')
plt.show()- 그리고 데이터 시각화는 기본적으로 생각하기에 가장 깔끔하고 이해가 잘되게끔 그래프를 적절히 편집하여 보여주는 것이 중요하다고 생각한다 !
- title은 그래프의 제목을 설정하고, x/y lable은 각 x,y축에 붙는 제목을 설정할 수 있다!
- pad는 제목과 그래프 사이의 간격을 조정하고, size는 제목의 크기를 설정한다.
plt.plot(stock['Day'], stock['Close'], 'go--')
plt.title('Stock Closing Price', size=15, pad=10)
plt.xlabel('Day')
plt.ylabel('Price')
plt.show()- 선 그래프 말고도 각 지점마다 점선을 찍는 스타일도 있는데 이때에는 초록색을 뜻하는 g, 점을 찍는 o , 점선을 뜻하는 -- 를 결합하여 plot 안에 정의한다.( 순서는 상관없다 ex) 'og--'


plt.plot(stock['Day'], stock['Open'], color='g', marker='o', linestyle='--')
plt.plot(stock['Day'], stock['Close'], color='r', marker='s', linestyle='--')
plt.title('Stock Price', size=15, pad=10)
plt.xlabel('Day')
plt.ylabel('Price')
plt.show()
plt.plot(stock['Day'], stock['Open'], 'o--', label='Open')
plt.plot(stock['Day'], stock['Close'], 's--', label='Close')
plt.title('Stock Price', size=15, pad=10)
plt.xlabel('Day')
plt.ylabel('Price')
plt.legend() # loc='upper left' 등으로 위치 변경 가능, default='best'
plt.grid() # axis 지정 가능 ('both', 'x', 'y')
plt.show()- 그리고 항상 나랑 아예 다른 domain에 있는 사람에게 설명하고 보여준다고 생각한다면 각 그래프에 대한 간단한 요소가 무엇인지 표현하는게 좋을 것 같다.
- legend는 각 그래프가 나타내는 데이터의 범례 정보를 나타내는데 plot에 y 축으로 정의된 값을 표시한다.
- grid는 괘선을 표시하여 더 정밀하게 보고싶을 때 사용하면 될 것 같다.
- 그래프 하나하나를 그리려면 코드도 그렇고 조금 번거로우니 subplot을 통해 한번에 시각화 시키는 방법이 있다.
- Subplot(행,열,순서) 라고 생각하면 된다.
- 그리고 tight_layout() 을 통해 여러 그래프가 겹치지 않도록 자동 조정되는 함수를 이용하여 더 보기 좋게 시각화 시킨다.
plt.subplot(2, 1, 1)
plt.plot(stock['Day'], stock['Open'], color='tab:blue', marker='o')
plt.title('Opening Price')
plt.subplot(2, 1, 2)
plt.plot(stock['Day'], stock['Close'], color='tab:orange', marker='s')
plt.title('Closing Price')
plt.tight_layout()
plt.show()
Seaborn
- Seaborn은 matplotlib과 같은 파이썬 시각화 라이브러리다.
- 사실 사용해보니 Seaborn을 더 사용하게 되는데, 훨씬 간편하고 직관적이며, 다양한 테마와 스타일을 지원한다.
- 둘은 서로 함께 사용되어 시각화가 더 보기 좋게 만들어지게 해준다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format='retina'
# Titanic 데이터
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/titanic_simple.csv'
titanic = pd.read_csv(path)
titanic.dropna(inplace=True)
# 확인
titanic.head()- 똑같이 import 해준뒤 as sns 로 축약해서 사용할 수 있도록 정의해준다.
- path를 통해 data를 불러오고 데이터 프레임 형태로 불러와서 titanic 으로 정의한다.
- dropna를 통해 nah 즉 결측치를 제거한 후 데이터 프레임을 수정한다.


sns.histplot(x='Age', data=titanic, bins=16, ec='k')
plt.show()- seaborn에서는 단일 변수의 데이터 분포를 histogram으로 표시한다.
- histplot(x축 변수, 참조 데이터프레임, x축 단위 갯수,막대 그래프 경계선 색깔) 으로 정의한다.
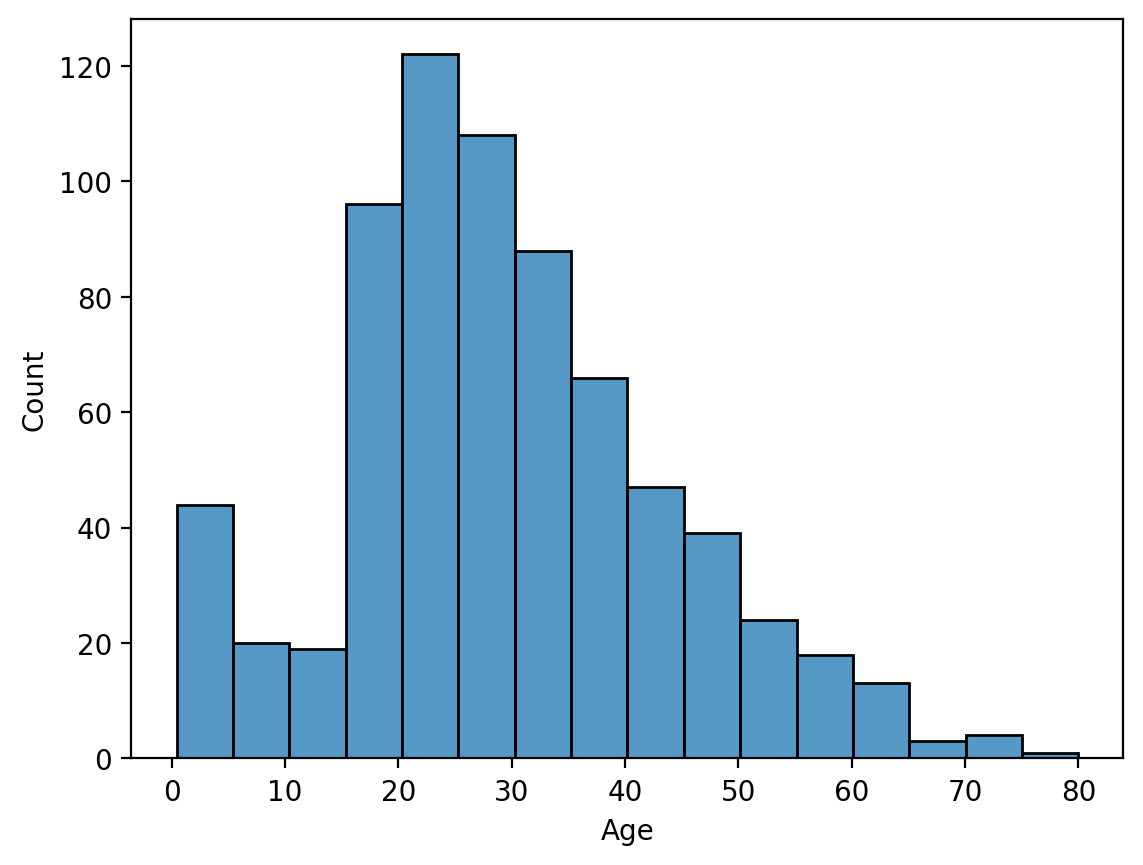
sns.histplot(x='Age', hue='Survived', data=titanic, bins=16, ec='k')
plt.show()- 그리고 여기서 범주형 변수를 구분 기준으로 이용하여 각 데이터마다 survived 비율 + matplotlib의 legend 역할을 해준다고 생각하면 된다.
sns.kdeplot(x='Age', data=titanic)
plt.show()- kdeplot은 데이터의 분포를 나타내는데 그래프 아래의 면적이 1이 되고, 숫자형 변수의 값 분포를 확인할 수 있다.
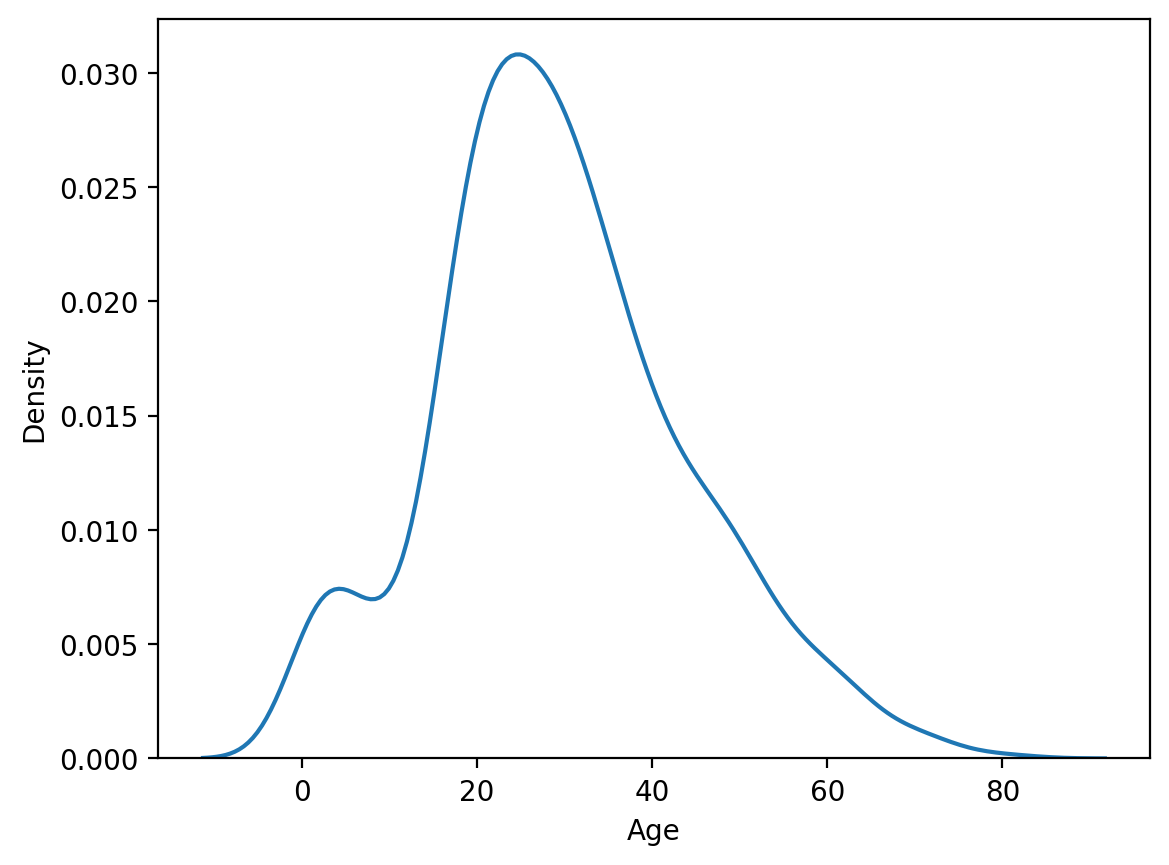
sns.kdeplot(x='Age', hue='Survived', data=titanic, common_norm=False)
plt.show()
sns.boxplot(y='Age', data=titanic)
plt.show()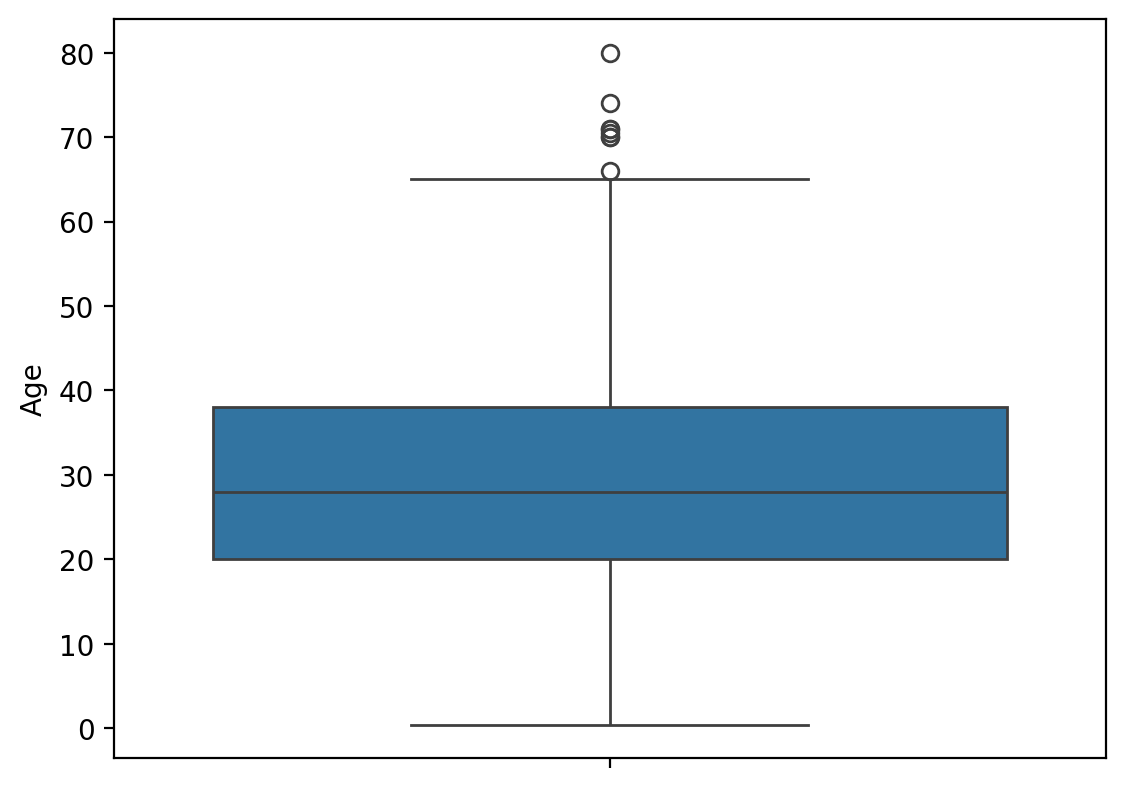
sns.boxplot(x='Age', y='Survived', data=titanic,orient='h')
plt.show()
여기서 x축의 범주와 달리 y축을 넣을 경우는 겹쳐서 나오기 때문에 ( 범주형일 경우 )
orient = 'h'를 정의하여 시각화 시킨다
728x90
반응형
'KT AIVLE SCHOOL 7기' 카테고리의 다른 글
| [KT AIVLE SCHOOL 7기] - 머신러닝(3) 튜닝 (0) | 2025.04.08 |
|---|---|
| [KT AIVLE SCHOOL 7기] - 머신러닝(2) 분류 (0) | 2025.04.08 |
| [KT AIVLE SCHOOL 7기] - 머신러닝(1) 회귀 (1) | 2025.04.08 |
| [KT AIVLE SCHOOL 7기] - Pandas(데이터프레임) (0) | 2025.04.07 |
| [KT AIVLE SCHOOL 7기] - 합격 후기 (0) | 2025.04.07 |
'KT AIVLE SCHOOL 7기' Related Articles
more



